为了让 Rust 编译得更快,我所做的努力 (2020)
这篇文章是 Mozilla 工程师 Nicholas 对从 2019 年 12 月到现在 (2020 年 5 月) 的工作总结,主要是对提升 Rust 编译器的编译速度而作的改进。
通过对这篇文章的学习,除了可以了解 Rust 编译器的新特性,更重要的是可以学习一些开发技巧和开发中需要注意的细节。
我上篇关于我为加快 Rust 编译器的所做工作的总结写于 2019 年 12 月。 是时候更新一波了。
增量编译🔗
我新年做的第一件事就是剖析增量编译并对此进行了一些改进。
#68914:增量编译通过一个被称为 SipHasher128 的哈希算法来处理大量数据,以确定自上一次编译以来更改了哪些代码。此 PR 极大地提升了从输入字节流中提取字节的过程 (通过多次实验以确保它在大端 (big-endian) 和小端 (little-endian) 平台上均可使用),在许多情况下,编译速度最高可提升 13%。 顺便还添加了更多注释来解释该代码中发生了什么,并删除了多个 unsafe。
#69332:此 PR 还原了 #68914 的一部分,该部分简化了 u8to64_le 函数,但同时又使其变得更慢。这对性能没有太大影响,因为它不是一项常用的功能,但我很高兴在还没有被更多人使用的情况下修复了它。 我还添加了一些解释性的注释,因此没有人会犯与我相同的错误!
#69050:LEB128 编码被广泛引用于 Rust 的 crate 存储的元数据 (metadata) 中。Michael Woerister 在之前的 #46919 中提升了 (rustc) 编码和解码 LEB128 的速度,但仍有一点慢。这个 PR 减少了编码和解码操作中的循环次数,几乎使它们的速度提高了一倍,并为整体贡献了高达 5% 的性能提升。 同时还消灭了一个 unsafe。在 PR 中,我对所采用的方法进行了详细说明,包括我是如何使用 Callgrind 进行性能分析,并发现可能的改进的。我先后尝试了 18 种不同的方法进行优化 (其中 10 种方法改善了速度),并且展示了最终的性能结果。
LLVM bitcode🔗
去年,我从配置文件中注意到 rustc 花费了一些时间来压缩它生成的 LLVM BitCode,尤其是在 Debug 模式下。 我尝试对其进行了改进,不压缩 BitCode,这样可以加快一些速度,但代价是磁盘上已编译工件的大小也显著增加。
然后 Alex Crichton 告诉了我一件很重要的事: 编译器总是为 crate 生成目标代码和 BitCode。正常编译时使用目标代码,而通过链接时间优化 (LTO) 进行编译时则使用 BitCode,这种情况很少见。 用户在这两种情况中二选一,因此同时生成两种代码通常会浪费时间和空间。
在 PR #66598 中,我提出了一个简单的方案解决这一问题: 增加一个新的 flag 告诉 rustc 不要生成 LLVM BitCode。然后,只要不使用 LOT,Cargo 便默认使用该 flag 进行编译。经过讨论,我们认为这一方案太过简陋了,于是我们开了个 issue #66961 以进行更广泛的讨论。最终通过的方案是使用未压缩的 BitCode 替代压缩 BitCode 储存为目标代码的一部分 (clang 使用的标准格式),并为 Cargo 引入了一个新的 flag 来禁用 BitCode 的生成,从而摆脱了对压缩 BitCode 的使用。
rustc 对这部分问题的处理有点混乱。编译器可以产生许多不同种类的输出: 汇编代码,目标代码,LLVM IR 和两种不同格式的 LLVM BitCode。 这些输出中的一些格式依赖于其他输出,产生什么样的格式的输出取决于各种命令行选项以及特定的目标平台。内部状态依赖许多布尔值来跟踪最终输出的产品,并且这些布尔值的各种无意义的组合都是可能的。
当我需要理解这些混乱的代码时,我的标准方法是开始重构。我编写了 #70289,#70345 和 #70384 来理清了代码生成的相关逻辑,#70297,#70729 和 #71374 来重构处理命令行选项的相关代码,以及用 #70644 来重构模块配置的相关代码。这些更改使我对代码有所了解,我着手简化代码,然后我编写了 #70458 以进行主要更改。
同时,Alex Crichton 为 Cargo 编写了新的 flag -Cembed-bitcode = no (并回答了我的很多问题)。 然后,我修改了 rustc-perf,以便它和新版的 rustc 和 Cargo 一起使用,否则,(原本优化性能的) 更改将在 CI 上错误的看起来像性能下降。 最后,我们的新命令行选项经历了的编译器团队全体人员的批准和最终意见征询期,从而可以投入使用。
不幸的是,在进行着陆前测试 (pre-landing tests) 时,我们发现某些链接器无法处理某些特殊部分中的 BitCode。仅在最后一分钟才发现此问题,因为只有那时所有的完整测试才会在所有平台上运行。Oh dear,是时候启动计划 B 了。我最终提交了 #71323,该代码回到了最初的简单方案,为 rustc 添加一个名为 -Cbitcode-in-rlib = no 的 flag。[EDIT: 值得注意的是,libstd 仍使用 -Cbitcode-in-rlib = yes 进行编译,这意味着 libstd rlibs 仍同时使用 LTO 和非 LTO 构建。]
最终结果显示,这是我所做的最大的性能改进之一。 对于 Debug 模式下,性能最高提升了 18%。而对于发布版本(opt builds),我们也可以看到高达 4% 的性能提升。rlibs 的大小也缩小了约 15-20%。 感谢 Alex 和他提供的所有帮助!
对于直接调用 rustc 而不是使用 Cargo 的进行编译的情况,需要加上 -Cbitcode-in-rlib = no 才能应用该特性。
[EDIT (May 7, 2020): Alex 通过在生成的代码适当的中添加 “ignore this section, linker” 字样,从而在 #71528 中实现了 bitcode-in-object-code-section。他随后在 #71716 中将选项名改回了 -Cembed-bitcode = no。再次感谢Alex!]
其他改进🔗
#67079:年在 #64545 中,我改进了 shallow_resolved 函数,该函数用于热调用模式 (hot calling pattern)。 此 PR 进一步改进了该函数,在几个基准测试中获得了 2% 的性能提升。
#67340:此 PR 将 Nonterminal 类型的大小从 240 字节缩减为 40 字节,从而减少了 memcpy 被调用的次数 (因为 memcpy 用于复制大于 128 字节的值),在一些基准测试中获得了高达 2% 的性能提升。
#68694:InferCtxt 中原本包含有七种不同数据结构的 RefCell。有几个常用的操作将依次借用大部分或全部 RefCell。 该 PR 将七种数据结构归为一个 RefCell,以减少执行借用的次数,性能最高提升了 5%。
#68790:此 PR 对 merge_from_succ 函数进行了一些小改进,在几个基准测试中获得 1% 的性能提升。
#68848:编译器的宏解析代码中包含一个循环,该循环在每次迭代时实例化一个较大的复杂值 (Parser 类型),但是这些迭代中的大多数情况并没有修改该值。该 PR 更改了代码,它在循环外初始化了一个 Parser,然后使用 Cow 避免克隆它 (除非迭代中修改了该值),从而使 html5ever 基准测试速度提高了 15%。(顺便一提:我已经使用过 Cow 好几次了,虽然这个概念很简单,但是我发现我很难记住相关细节。每次都必须重新阅读文档。使代码正常工作总是很麻烦,而且我从来没有信心能让它成功编译……但是每次我写完后它却可以正常工作。)
#69256:此 PR 优化了一些与 #[inline] 标记相关的读写元数据的常用函数,优化后的性能在多个基准测试中均提高了 1-5%。
#70837:有一个名为 find_library_crate 的函数,其功能恰如其名。它对储存在 PathBufs 中的文件名进行了很多重复的前缀和后缀匹配。匹配速度很慢,其中涉及到在 PathBuf 方法中进行大量路径的重新解析,因为 PathBuf 并不是真正为干这种活而设计的。 该 PR 抢先提取了相关文件的名称,并以字符串的形式将其存储在 PathBuf 中,然后使用这些字符串作为代替进行匹配,从而在各种基准测试中获得了高达 3% 的性能提升。
#70876:Cache::predecessors 是一个经常被调用的函数,它为 vectors 产生 vector (这一句不是很懂,不知道翻译对没有,原文是: “produces a vector of vectors”),而且内部 vector 通常很小。此 PR 将内部 vector 更改为 SmallVec;此优化在各种基准测试中获得了一个非常小的性能提升,最高可达 0.5%。
其他🔗
我为 rustc-perf 添加了对编译器的自我分析器 (compiler’s self-profiler) 的支持。 这为我们运行在本地计算机上的基准测试套件 (benchmark suite) 提供了一个新的分析工具。
我发现在构建 rustc 时使用 LLD 作为链接器可以将链接所花费的时间从大约 93 秒减少到大约 41 秒。(在我Linux 机器上,我通过在 build 命令之前设置 RUSTFLAGS ="-C link-arg = -fuse-ld = lld" 来执行此操作。) LLD 是一个非常快的链接器!#39915 是一个已存在了三年的 issue,其讨论使 LLD 成为 rustc 的默认链接器,但不幸的是,它停滞不前。 Alexis Beessner 撰写了一份有关当前情况的不错的摘要。如果任何有相关知识的人能解决这个 issue,对于 Rust 用户来说,这可能是一个巨大的性能提升点。
失败案例🔗
并非我尝试过的所有方法都奏效。 这是一些失败案例。
#69152:如上所述,#68914 大大改进了 SipHasher128,它是增量编译中被使用的哈希函数。该哈希函数 Rust 哈希表 (Rust hash tables) 使用的默认 64 位哈希函数的 128 位版本。 我尝试将这些改进移植到默认哈希器 (hasher) 中。其目的不是提高 rustc 的速度,因为它使用 FxHasher 而不是默认的哈希算法,而是要提高所有使用默认哈希的 Rust 程序的速度。不幸的是,由于 PR 中详细讨论的复杂原因,这导致了一些编译时回归 (compile-time regressions),因此我放弃了它。 但我设法在 #69471 删除了默认哈希器中的一些无效代码。
#69153:在处理 #69152 时,我尝试让 rustc 中的所有哈希表从 FxHasher 切换回改进的默认哈希器 (即它最终没有成功)。结果堪比灾难;每一个基准测试的成绩都下降了! 最小的降幅是 4%,最大的是 85%。这说明了 (a) rustc 使用了大量的哈希表,以及 (b) 使用小哈希键 (small keys) 时 FxHasher 的速度比默认的哈希算法快很多。
我尝试让 rustc 中的所有哈希表使用 ahash。它被宣传为与 FxHasher 一样快,但质量更高。 我发现它使 rustc 的性能有小幅度的降低。另外,ahash 在不同的 build 之间也存在不确定性,因为它在初始化哈希器状态时使用了 const_random!。 这可能会在性能运行中引起额外的噪声 (noise),这很糟糕。(Edit: 它还会阻止了 Reproducible builds,这也很糟糕。)
我尝试将用于增量编译的 SipHasher128 函数从 Sip24 算法更改为速度更快但质量更低的 Sip13 算法。此举获得了高达 3% 的性能提升,但由于对其安全性没有信心,所以没有进一步研究。
#69157:在 #69050 之后进行的一系列后续测试表明,它对 LEB128 解码的性能提升并不像第一次测试时那样明显。(对编码的改进是可以确定的。) 解码的性能表现似乎对非本地改变 (non-local changes) 更加敏感,这可能是由于解码函数在整个编译器中的内联方式不同。此 PR 恢复了 #69050 的部分更改,因为我的初步跟踪测试表明其对性能的提升可能是悲观的。但是随后在多次变基 (rebasing) 后进行的几组其他后续测试表明,还原后的代码有时性能会降低。还原还会使代码变得更加丑陋,因此我放弃了此 PR。
#66405:ObligationForest 持有的每个 obligation 可以处于多个状态之一,并且这些状态之间随时可能发生转换。 此 PR 将状态的数量从五个减少到三个,并且大幅减少了发生状态转换的数量,在某些基准测试中,其带来了最多 4% 的性能提升。但是,它最终导致了一些用户出现性能的大幅度降低,因此在 #67471 中,我还原了这些更改。
#60608:这个 issue 建议在某些地方使用 FxIndexSet 代替当前使用的 FxHashMap + Vec 。我在 symbol table 中进行了尝试,这降低了一些基准测试成绩。
性能比较🔗
自从我上一篇博客文章以来,编译器性能有了长足进步。以下截图展示了自那时以来 (2019-12-08 至 2020-04-22) 基准测试套件给出的完成测试时间的变化 (wall-time changes)。
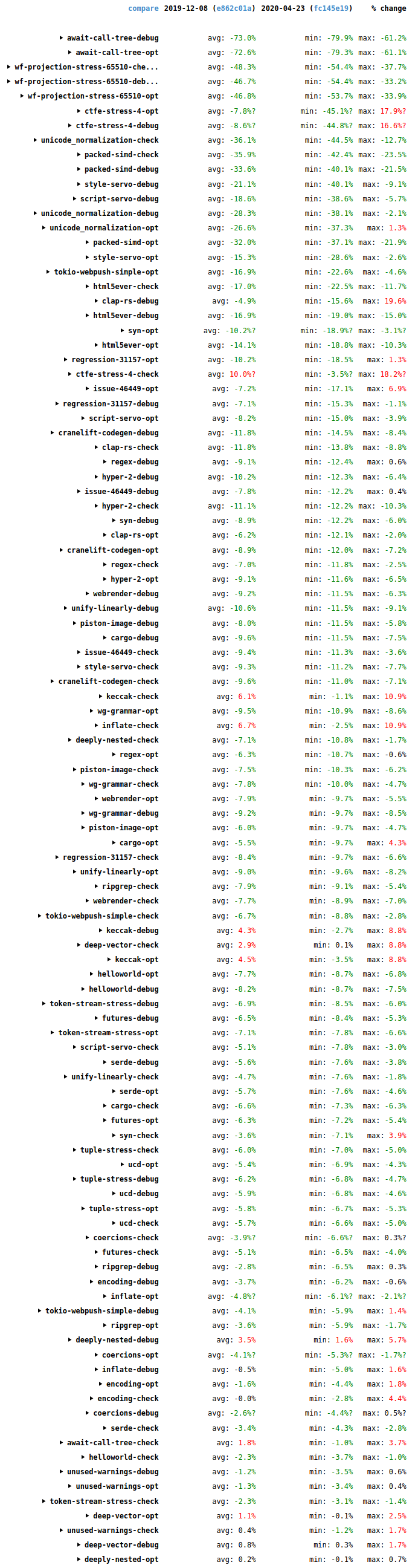
最大的性能提升是综合压力测试 await-call-tree-debug,wf-projection-stress-65510 和 ctfe-stress-4,不过它们测试的项目不是特别的典型,所以也不是那么重要。
总体而言,这是个好消息,它带来了很多的性能提升 (绿色),有些提升幅度甚至是两位数,而性能降低的项目却很少 (红色)。非常感谢在此期间为所有为改进编译器性能提供帮助的人。
译者:Mogeko
原文作者:Nicholas Nethercote